How does Google Bot Process JavaScript?
Google started ‘seeing’ JavaScript (JS) and CSS web pages in 2015.
Processing JS powered sites in three phases: crawling, rendering, and indexing.
For your site to be crawlable Google must be able to read your robots.txt file.
Parsing the information to all the other URLs in the href attribute and then adding the URL to the crawl queue; commonly referred to as indexing.
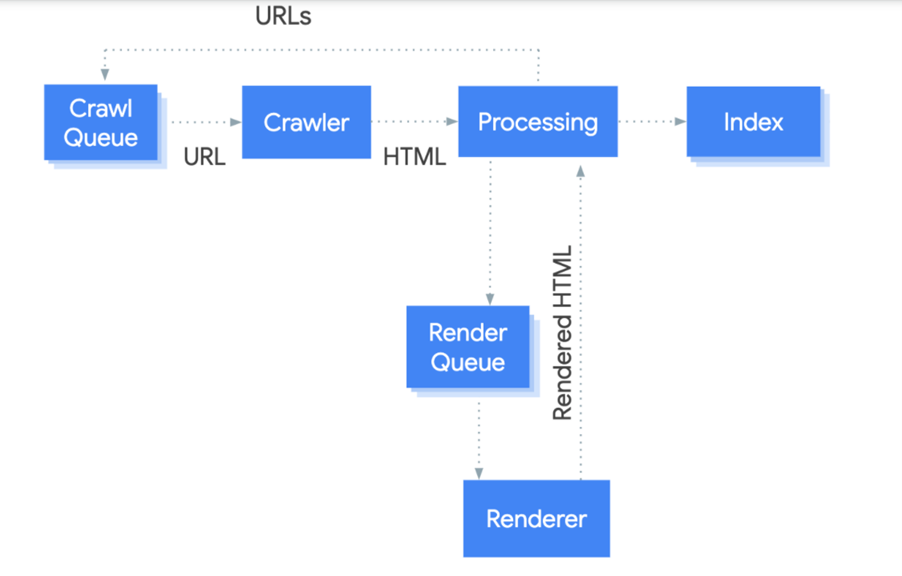
In the past, Google preferred the successive improvement of HTML sites to JS pages. But with recent updates to Google Caffeine – the official rendering engine for Google- crawling and rendering of JS powered sites has significantly improved.
How does JavaScript Affect SEO?
Developers may love the rich interface and easy to implement framework of JavaScript. But the same perks also affect SEO because it makes it possible for browser fluidity to change based on user interaction. Making it difficult for search engines to crawl (understand) the pages and index the content. If your site isn’t indexed then your pages won’t be discoverable in organic searches.
But there’s a work around. Once you understand how JavaScript works, what client-side and server-side rendering is, and how Google handles rendering of JS websites- you can reduce its impact to your site. You’ll use client-side JavaScript rendering for apps and sites where interactivity is more important than ranking. Shifting to hybrid rendering where content is more critical.
Why is it Difficult for Search Engines to Crawl JavaScript?
Unlike HTML, CSS, PHP, and other programming languages which can directly be crawled by search engines. Such that the source code is rendered as soon as the URL is called up. With JS, such a direct approach isn’t possible.
Here’s how Google crawls a JavaScript website:
- Googlebot downloads the html file.
- Googlebot doesn’t find any links in the source code and moves on to downloading the CSS and JS files.
- Google Caffeine parses, compiles and executes JavaScript.
- External APIs from the database are fetched and the content is indexed.
- Google can now add the link to Googlebot’s crawling queue.
As you can see, rendering and indexing JS is a bit more complicated. Making it difficult for search engines to crawl the pages.
Is it only Google Search Engine that Renders JavaScript
Apart from Google, Bing is the only other Search Engine that renders JavaScript websites.
The updates to Bingbot which were made in 2018 generally allow it to process and index JS sites but with some limitations.
For one thing, Bingbot doesn’t support all the recent updates to JS framework. Processing every page of every website while simultaneously reducing the number of HTTP requests made also presents a challenge for Bingbot.
To make up for the above, websites that rely heavily on JavaScript should consider using dynamic rendering. It will increase the predictability of crawling and indexing by Bing.
What are Some of the Most Common JavaScript SEO Mistakes and How Can You Fix Them?
The most common JS SEO mistake is expecting Googlebot to index pages that require user permission. Since Googlebot and WRS- the web rendering service- clear local storage, session data, and HTTP cookies, data persistence won’t allow the pages to be rendered and indexed.
You should also know that WebGL is also not supported by Googlebot. Which means that the photo effect rendered using the former won’t reflect on your site. Using server-side rendering instead to pre-render your photo effects will fix this problem for you.
Another thing JS site owners often forget to address is the user friendly issue. Putting your web components into a light Document Object Model (DOM) eliminates the brittleness emanating from programming languages. Ensuring the content on your website is search friendly.
When it comes to search, it’s universally acknowledged that the more mobile friendly your site is the higher your chances of ranking favorably. So how can JS-powered sites enjoy the same kind of success (if not more) as their counterparts?
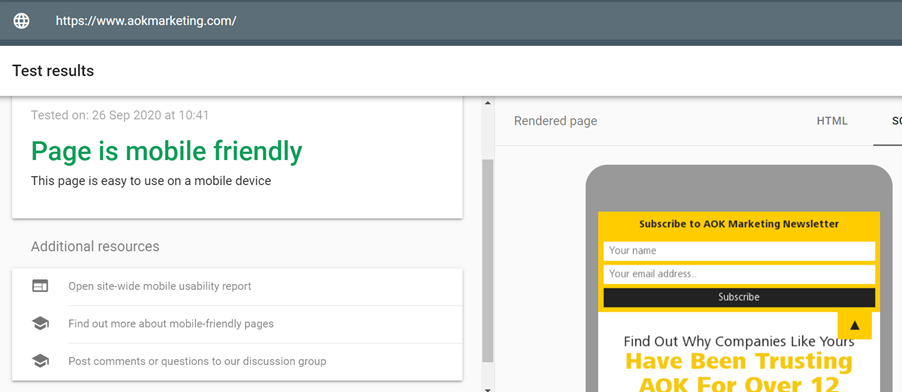
The first step is to test your site using a handy tool from Google. Enter the search phrase ‘check mobile friendly’.
Wait a few seconds and you’ll find out exactly how mobile friendly your site really is:
What are the Common Must-Haves for JavaScript Websites that SEOs Overlook?
Implementing JS-powered sites without considering SEO can have serious consequences on page performance. From render-blocking issues to limiting crawlability of content and drastically reducing page speed. Although every website is different and serves a specific variety of audience; here are some common must haves for JavaScript websites:
- Use History API to assign all your pages with a unique URL.
- Opt for server side rendering or pre-rendering to make it easier for search engine crawlers to access your URLs.
- Don’t forget to link all your pages internally. If you’re using JS to load in page content, also link everything with HTML.
How do you Check the Crawlability of a JS-Powered Site?
All your research on target keywords and creation of unique relevant content is only effective if Google can crawl your JS-powered site. Which makes conducting a crawl test a critical part of the JavaScript SEO process. Here’s how to check the crawlability of your site:
Step One
Turn off JS in your browser using a plugin like Disable JavaScript or Quick JavaScript Switcher.
Step Two
Use a tool like Screaming Frog to see which parts of your sites are crawled and which ones aren’t. For site owners using pre-rendering, it’s also a good idea to crawl with Googlebot as a User Agent.
Step Three
Use Screaming Frog with JavaScript rendering to crawl your site. Store both the HTML and rendered HTML so you can compare them. The data from the crawls can help identify crawlability issues and allow you to get ahead of them. Such that search engines have no problem reading and indexing your pages.
Remember;
-All the links listed in the HTML file are crawlable.
-Items in the rendered HTML represent links that are only visible after rendering.
-Everything else that doesn’t appear in the two files cannot be crawled.



